3种系统架构与2种存储器共享方式
架构概述
- 从系统架构来看,目前的商用服务器大体可以分为三类
- 对称多处理器结构(SMP:Symmetric Multi-Processor)
- 非一致存储访问结构(NUMA:Non-Uniform Memory Access)
- 海量并行处理结构(MPP:Massive Parallel Processing)。
- 共享存储型多处理机有两种模型
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)模型
- 非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型
SMP(Symmetric Multi-Processor)
- 所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。
- 各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)
- 对SMP服务器进行扩展的方式包括增加内存、使用更快的CPU、增加CPU、扩充I/O(槽口数与总线数)以及添加更多的外部设备(通常是磁盘存储)。
- SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。
- 对于SMP服务器而言,每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU
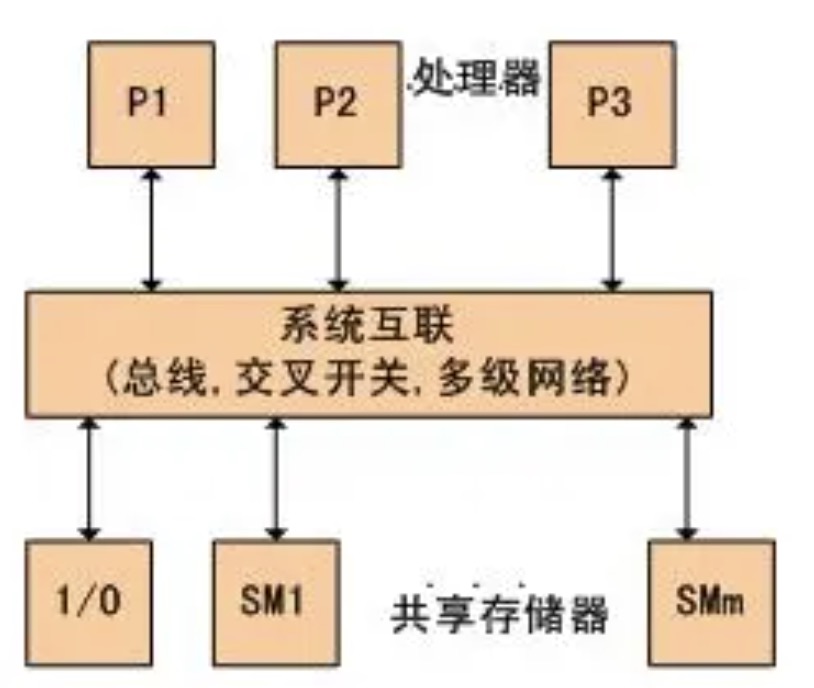
图中,物理存储器被所有处理机均匀共享。所有处理机对所有存储字具有相同的存取时间,这就是为什么称它为均匀存储器存取的原因。每台处理机可以有私用高速缓存,外围设备也以一定形式共享
NUMA(Non-Uniform Memory Access)
为什么要有NUMA
在NUMA架构出现前,CPU欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个core的工作性质都是share-nothing(类似于map-reduce的node节点的作业属性),那么也许就不会有NUMA。由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个die上。于是NUMA就出现了
传统来说,主板上两个主要芯片,靠上方的叫北桥,靠下方的叫南桥。大体上说:北桥负责与CPU通信,并且连接高速设备(内存/显卡),并且与南桥通信;南桥负责与低速设备(硬盘/USB)通信,时钟/BIOS/系统管理/旧式设备控制,并且与北桥通信。
Intel从第一代Core i7 (i7 9xx)开始,将原属于北桥功能的内存控制器整合到CPU当中,在主流机Core i中(i7 8xx)更将PCI-e控制器(主要负责连接显卡)整合到CPU当中,这时候传统意义上的北桥的所有功能都已经整合到CPU内部了,所以Intel 50系芯片“组”(X58除外,这是搭配i7 9xx用的,还有北桥)已经没有传统意义的北桥了,而南桥依然负责处理低速设备(SATA/USB/PCI等)、时钟等功能。由于只剩下一个芯片了,也没有“芯片组”的说法了,只剩下孤零零的PCH (Platform Controller Hub)。
AMD平台的发展轨迹类似,在K8架构(第一代AMD64处理器)开始就把内存控制器集成到CPU内部,后来先是APU再是桌面的FX系列,陆陆续续把PCI-e控制器也整合到CPU中,也剩下孤零零的FCH (Fusion Controller Hub)……于是这两家的南桥(PCH/FCH)现在差不多变成了一个PCI-e Hub了……至于说多出来的空间……如果还是ATX大板的话,现在主板厂商流行在原来布置北桥的地方放个M.2接口(哦这是近两年,前几年还没这接口的时候高端板流行塞一大个散热片显得很帅,低端板就空置了……)。另一种形式是出现了mini-ITX结构的主板,把主板直接缩小了,这在以前南北桥的年代基本是不可想象的。
NUMA是什么
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。
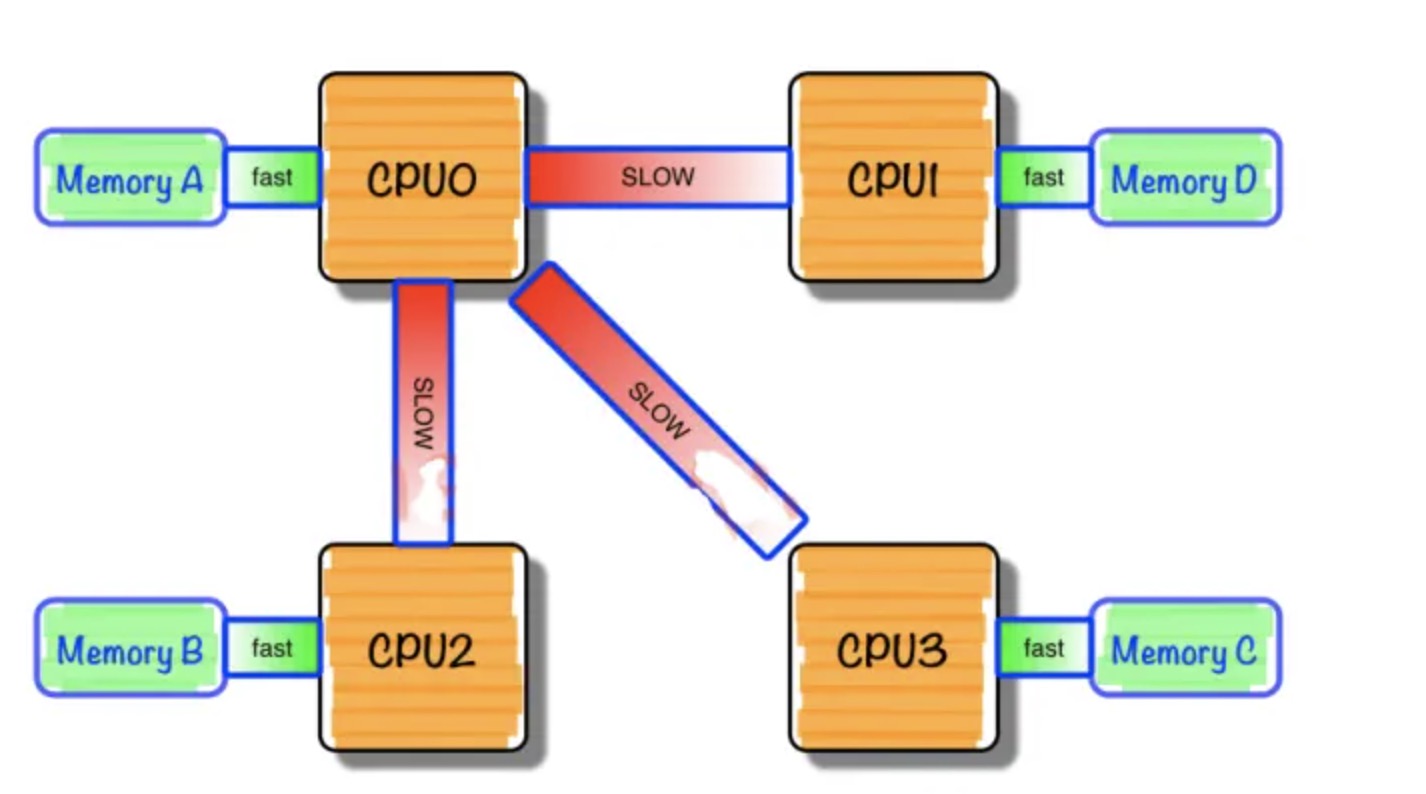
我们需要为NUMA做什么
假设你是Linux教父Linus,对于NUMA架构你会做哪些优化?下面这点是显而易见的:
既然CPU只有在Local-Access时响应时间才能有保障,那么我们就尽量把该CPU所要的数据集中在他local的内存中就OK啦~
没错,事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped
NUMA的“七宗罪”
几乎所有的运维都会多多少少被NUMA坑害过,让我们看看究竟有多少种在NUMA上栽的方式:
- MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture
- PostgreSQL – PostgreSQL, NUMA and zone reclaim mode on linux
- Oracle – Non-Uniform Memory Access (NUMA) architecture with Oracle database by examples
- Java – Optimizing Linux Memory Management for Low-latency / High-throughput Databases
究其原因几乎都和:“因为CPU亲和策略导致的内存分配不平均”及“NUMA Zone Claim内存回收”有关,而和数据库种类并没有直接联系。所以下文我们就拿MySQL为例,来看看重内存操作应用在NUMA架构下到底会出现什么问题。 MySQL在NUMA架构上会出现的问题 几乎所有NUMA + MySQL关键字的搜索结果都会指向:Jeremy Cole大神的两篇文章
- The MySQL “swap insanity” problem and the effects of the NUMA architecture
- A brief update on NUMA and MySQL
大神解释的非常详尽,有兴趣的读者可以直接看原文。博主这里做一个简单的总结:
- CPU规模因摩尔定律指数级发展,而总线发展缓慢,导致多核CPU通过一条总线共享内存成为瓶颈
- 于是NUMA出现了,CPU平均划分为若干个Chip(不多于4个),每个Chip有自己的内存控制器及内存插槽
- CPU访问自己Chip上所插的内存时速度快,而访问其他CPU所关联的内存(下文称Remote Access)的速度相较慢三倍左右
- 于是Linux内核默认使用CPU亲和的内存分配策略,使内存页尽可能的和调用线程处在同一个Core/Chip中
- 由于内存页没有动态调整策略,使得大部分内存页都集中在CPU 0上
- 又因为Reclaim默认策略优先淘汰/Swap本Chip上的内存,使得大量有用内存被换出
- 当被换出页被访问时问题就以数据库响应时间飙高甚至阻塞的形式出现了
解决方案
Jeremy Cole大神推荐的三个方案如下,如果想详细了解可以阅读 原文
- numactl –interleave=all
- 在MySQL进程启动前,使用sysctl -q -w vm.drop_caches=3清空文件缓存所占用的空间
- Innodb在启动时,就完成整个Innodb_buffer_pool_size的内存分配
这三个方案也被业界普遍认可可行,同时在 Twitter 的5.5patch 和 Percona 5.5 Improved NUMA Support 中作为功能被支持。 不过这种三合一的解决方案只是减少了NUMA内存分配不均,导致的MySQL SWAP问题出现的可能性。如果当系统上其他进程,或者MySQL本身需要大量内存时,Innodb Buffer Pool的那些Page同样还是会被Swap到存储上。于是又在这基础上出现了另外几个进阶方案
- 配置vm.zone_reclaim_mode = 0使得内存不足时去remote memory分配优先于swap out local page
- echo -15 > /proc/
/oom_adj调低MySQL进程被OOM_killer强制Kill的可能 - memlock
- 对MySQL使用Huge Page(黑魔法,巧用了Huge Page不会被swap的特性)
MPP(Massive Parallel Processing)
- 和NUMA不同,MPP提供了另外一种进行系统扩展的方式,它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制,目前的技术可实现512个节点互联,数千个CPU。目前业界对节点互联网络暂无标准,如 NCR的Bynet,IBM的SPSwitch,它们都采用了不同的内部实现机制。但节点互联网仅供MPP服务器内部使用,对用户而言是透明的。
- 在MPP系统中,每个SMP节点也可以运行自己的操作系统、数据库等。但和NUMA不同的是,它不存在异地内存访问的问题。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。
- 但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。目前一些基于MPP技术的服务器往往通过系统级软件(如数据库)来屏蔽这种复杂性。举例来说,NCR的Teradata就是基于MPP技术的一个关系数据库软件,基于此数据库来开发应用时,不管后台服务器由多少个节点组成,开发人员所面对的都是同一个数据库系统,而不需要考虑如何调度其中某几个节点的负载
3种体系架构之间的差异
NUMA、MPP、SMP之间性能的区别
- NUMA的节点互联机制是在同一个物理服务器内部实现的,当某个CPU需要进行远地内存访问时,它必须等待,这也是NUMA服务器无法实现CPU增加时性能线性扩展。
- MPP的节点互联机制是在不同的SMP服务器外部通过I/O实现的,每个节点只访问本地内存和存储,节点之间的信息交互与节点本身的处理是并行进行的。因此MPP在增加节点时性能基本上可以实现线性扩展。
- SMP所有的CPU资源是共享的,因此完全实现线性扩展。
NUMA、MPP、SMP之间扩展的区别
NUMA理论上可以无限扩展,目前技术比较成熟的能够支持上百个CPU进行扩展。如HP的SUPERDOME。 MPP理论上也可以实现无限扩展,目前技术比较成熟的能够支持512个节点,数千个CPU进行扩展。 SMP扩展能力很差,目前2个到4个CPU的利用率最好,但是IBM的BOOK技术,能够将CPU扩展到8个。 MPP是由多个SMP构成,多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务。
MPP和SMP、NUMA应用之间的区别
- MPP的优势
- MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。由于MPP系统因为要在不同处理单元之间传送信息,在通讯时间少的时候,那MPP系统可以充分发挥资源的优势,达到高效率。也就是说:操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好。因此,MPP系统在决策支持和数据挖掘方面显示了优势。
- SMP的优势
- MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点。在通讯时间多的时候,那MPP系统可以充分发挥资源的优势。因此当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。
- NUMA架构的优势
- NUMA架构来看,它可以在一个物理服务器内集成许多CPU,使系统具有较高的事务处理能力,由于远地内存访问时延远长于本地内存访问,因此需要尽量减少不同CPU模块之间的数据交互。显然,NUMA架构更适用于OLTP事务处理环境,当用于数据仓库环境时,由于大量复杂的数据处理必然导致大量的数据交互,将使CPU的利用率大大降低。
系统架构的总结
- 传统的多核运算是使用SMP(Symmetric Multi-Processor )模式:将多个处理器与一个集中的存储器和I/O总线相连。所有处理器只能访问同一个物理存储器,因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,SMP的缺点是可伸缩性有限,因为在存储器和I/O接口达到饱和的时候,增加处理器并不能获得更高的性能,与之相对应的有AMP架构,不同核之间有主从关系,如一个核控制另外一个核的业务,可以理解为多核系统中控制平面和数据平面。
- NUMA模式是一种分布式存储器访问方式,处理器可以同时访问不同的存储器地址,大幅度提高并行性。 NUMA模式下,处理器被划分成多个”节点”(node), 每个节点被分配有的本地存储器空间。 所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点内的存储器所花的时间要少得多。
- NUMA 的主要优点是伸缩性。NUMA 体系结构在设计上已超越了 SMP 体系结构在伸缩性上的限制。通过 SMP,所有的内存访问都传递到相同的共享内存总线。这种方式非常适用于 CPU 数量相对较少的情况,但不适用于具有几十个甚至几百个 CPU 的情况,因为这些 CPU 会相互竞争对共享内存总线的访问。NUMA 通过限制任何一条内存总线上的 CPU 数量并依靠高速互连来连接各个节点,从而缓解了这些瓶颈状况
CPU亲和性及缓存
CPU亲和性
何为CPU的亲和性
CPU的亲和性,进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性,进程迁移的频率小就意味着产生的负载小。亲和性一词是从affinity翻译来的,实际可以称为CPU绑定。
在多核运行的机器上,每个CPU本身自己会有缓存,在缓存中存着进程使用的数据,而没有绑定CPU的话,进程可能会被操作系统调度到其他CPU上,如此CPU cache(高速缓冲存储器)命中率就低了,也就是说调到的CPU缓存区没有这类数据,要先把内存或硬盘的数据载入缓存。而当缓存区绑定CPU后,程序就会一直在指定的CPU执行,不会被操作系统调度到其他CPU,性能上会有一定的提高。
另外一种使用CPU绑定考虑的是将关键的进程隔离开,对于部分实时进程调度优先级提高,可以将其绑定到一个指定CPU核上,可以保证实时进程的调度,也可以避免其他CPU上进程被该实时进程干扰。
我们可以手动地为其分配CPU核,而不会过多的占用同一个CPU,所以设置CPU亲和性可以使某些程序提高性能。
Linux操作系统的CPU亲和性特征
操作系统部分Linux的调度程序同时提供”软CPU亲和性”和”硬CPU亲和性”
- 软亲和性:进程要在指定的 CPU 上尽量长时间地运行而不被迁移到其他CPU。
- Linux 内核进程调度器天生就具有被称为 软 CPU 亲和性(affinity) 的特性,因此linux通过这种软的亲和性试图使某进程尽可能在同一个CPU上运行。
- 硬亲和性:将进程或者线程绑定到某一个指定的cpu核运行
- 虽然Linux尽力通过一种软的亲和性试图使进程尽量在同一个处理器上运行,但它也允许用户强制指定进程无论如何都必须在指定的处理器上运行。
硬亲和性场景:需要保持高CPU缓存命中率时、需要测试复杂的应用程序时。
保持高CPU缓存命中率:如果一个给定的进程迁移到其他地方去了,那么它就失去了利用 CPU 缓存的优势。实际上,如果正在使用的 CPU 需要为自己缓存一些特殊的数据,那么所有其他 CPU 都会使这些数据在自己的缓存中失效。因此,如果有多个线程都需要相同的数据,那么将这些线程绑定到一个特定的 CPU 上是非常有意义的,这样就确保它们可以访问相同的缓存数据(或者至少可以提高缓存的命中率)。否则,这些线程可能会在不同的 CPU 上执行,这样会频繁地使其他缓存项失效。
测试复杂的应用程序:考虑一个需要进行线性可伸缩性测试的应用程序。有些产品声明可以在使用更多硬件时执行得更好。 我们不用购买多台机器(为每种处理器配置都购买一台机器),而是可以:1.购买一台多处理器的机器;2.不断增加分配的处理器;3.测量每秒的事务数;4.评估结果的可伸缩性。
在Linux操作系统中修改CPU亲和性的手段
在Linux内核中,所有的进程都有一个相关的数据结构,称为 task_struct。这个结构非常重要,其中与 亲和性(affinity)相关度最高的是 cpus_allowed 位掩码。这个位掩码由 n 位组成,与系统中的 n 个逻辑处理器对应。 具有 4 个物理 CPU 的系统可以有 4 位。如果这些 CPU 都启用了超线程,那么这个系统就有8个位掩码。 如果为给定的进程设置了给定的位,那么这个进程就可以在相关的 CPU 上运行。因此,如果一个进程可以在任何 CPU 上运行,并且能够根据需要在处理器之间进行迁移,那么位掩码就全是 1。这是 Linux 中进程的预设状态!
Linux 内核 API 提供了一些方法,让用户可以修改位掩码或查看当前的位掩码,控制和绑定进程在特定的CPU:
- sched_set_affinity() (用来修改位掩码)
- sched_get_affinity() (用来查看当前的位掩码)
- cpus_allowed(用于控制进程可以在哪里处理器上运行)
- sched_setaffinity(用于某个进程绑定到一个特定的CPU)
名词解释
- 物理CPU:机器上实际安装的CPU个数,比如说你的主板上安装了一块8核CPU,那么物理CPU个数就是1个,所以物理CPU个数就是主板上安装的CPU个数。
- 逻辑CPU:一般情况,我们认为一颗CPU可以有多个核,加上intel的超线程技术(HT), 可以在逻辑上再分一倍数量的CPU core出来。
- 超线程技术(Hyper-Threading):就是利用特殊的硬件指令,把单个物理CPU模拟成两个CPU(逻辑CPU),实现多线程。我们常听到的双核四线程/四核八线程指的就是支持超线程技术的CPU。
CPU高速缓存
基本原理
现代计算机处理器是基于一种叫对称多处理 (symmetric multiprocessing, SMP) 的概念。在一个 SMP 系统里,处理器的设计使两个或多个核心连接到一片共享内存 (也叫做主存,RAM)。另外,为了加速内存访问,处理器有着不同级别的缓存,分别是 L1、L2 和 L3。确切的体系结构可能因供应商、处理器模型等等而异。然而,目前最流行的模型是把 L1 和 L2 缓存内嵌在 CPU 核心本地,而把 L3 缓存设计成跨核心共享:
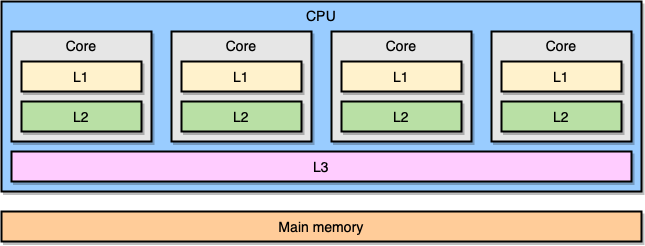
越靠近 CPU 核心的缓存,容量就越小,同时访问延迟就越低 (越快):
| Cache | Latency | CPU cycles | Size |
|---|---|---|---|
| L1 access | ~1.2 ns | ~4 | Between 32 KB and 512 KB |
| L2 access | ~3 ns | ~10 | Between 128 KB and 24MB |
| L3 access | ~12 ns | ~40 | Between 2 MB and 32 MB |
同样的,这些具体的数字因不同的处理器模型而异。不过,我们可以做一个粗略的估算:假设 CPU 访问主存需要耗费 60 ns,那么访问 L1 缓存会快上 50 倍。
在处理器的世界里,有一个很重要的概念叫访问局部性 (locality of reference),当处理器访问某个特定的内存地址时,有很大的概率会发生下面的情况:
- CPU 在不久的将来会去访问相同的地址:这叫时间局部性 (temporal locality)原则。
- CPU 会访问特定地址附近的内存地址:这叫空间局部性 (spatial locality)原则。
之所以会有 CPU 缓存,时间局部性是其中一个重要的原因。不过,我们到底应该怎么利用处理器的空间局部性呢?比起拷贝一个单独的内存地址到 CPU 缓存里,拷贝一个缓存行 (Cache Line)是更好的实现。一个缓存行是一个连续的内存段。 缓存行的大小取决于缓存的级别 (同样的,具体还是取决于处理器模型)。举个例子,这是我的电脑的 L1 缓存行的大小:
$ sysctl -a | grep cacheline
hw.cachelinesize: 64
处理器会拷贝一段连续的 64 字节的内存段到 L1 缓存里,而不是仅仅拷贝一个单独的变量。举个例子,当处理器要拷贝一个由 int64 类型组成 Go 的切片到 CPU 缓存里的时候,它会一起拷贝 8 个元素,而不是单单拷贝 1 个。
一个具体应用缓存行的 Go 程序
让我们来看一个具体的例子,这个例子将会给我们展示利用 CPU 缓存带来的好处。下面的代码完成的功能是合并两个由 int64 类型组成的方形矩阵
func BenchmarkMatrixCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[i][j]
}
}
}
}
给定的 matrixLength 变量值设为 64k,压测结果如下:
BenchmarkMatrixSimpleCombination-64000 8 130724158 ns/op
现在,我们把加 matrixB[i][j] 的操作换成 matrixB[j][i] :
func BenchmarkMatrixReversedCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[j][i]
}
}
}
}
改动之后对压测结果的影响有多大呢?
BenchmarkMatrixCombination-64000 8 130724158 ns/op
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
性能大幅下降!那该怎么解释这个结果呢?
让我们画几幅图来更直观地描述一下中间到底发生了什么,蓝色圆圈代表第一个矩阵的当前指针而粉红色圆圈代表了第二个矩阵的指针。由于程序的操作是
matrixA[i][j] = matrixA[i][j] + matrixB[j][i]
所以当蓝色指针处于坐标 (4,0) 之时,粉红色指针对应的坐标就是 (0,4)
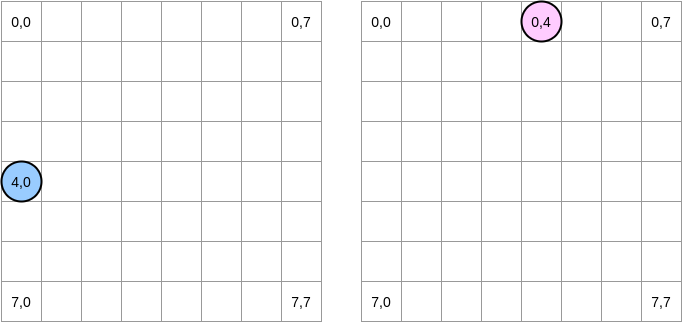
在上面的图解中,我们用横坐标纵坐标来表示矩阵,(0,0) 代表顶上最左的方块。从计算机原理的角度,一个矩阵所有的行将会被分配到一片连续的内存上,不过为了更直观地表示,我们还是按照数学的表示方法。
此外,接下来的例子里,矩阵的大小是缓存行大小的倍数。因此,一个缓存行不会在下一个矩阵行溢出。
程序会怎么遍历矩阵?蓝色指针会一直向右移动直到最后一列,然后移到下一行,到达坐标 (5,0),以此类推。相反地,粉红色指针会一直往下移动直到最后一行,然后移到下一列。
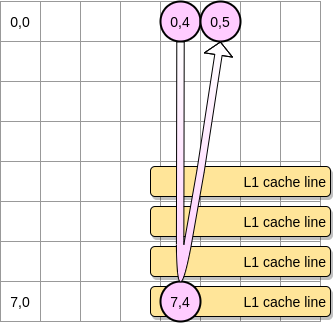
当粉红色指针在坐标 (0,4) 之时,处理器会缓存指针所在那一行 (在这个示意图里,我们假设缓存行的大小是 4 个元素):
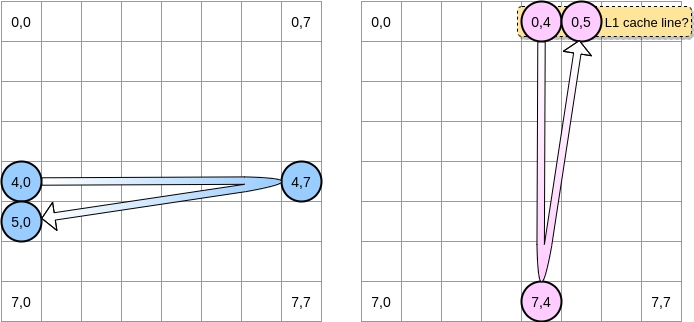
因此,当粉红色指针到达坐标 (0,5) 之时,我们可能会假定这个变量已经在 L1 缓存里了对不对?实际上这取决于矩阵的大小:
- 如果矩阵足够小从而所有的缓存行都能被容纳在 L1 里,那答案就是肯定的。
- 否则的话,该缓存行就会在指针达到 (0,5) 之前就被清出 L1。因此,将会产生一个缓存缺失,然后处理器就不得不通过别的方式访问该变量 (比如从 L2 里去取)。此时,程序的状态将会是这样的:
那么矩阵的容量应该达到多小才能从 L1 缓存中获益呢?让我们做个简单的计算:首先,我们需要知道 L1 缓存的容量有多大:
$ sysctl hw.l1icachesize
hw.l1icachesize: 32768
在我的机器上,L1 缓存的大小是 32768 字节而缓存行的大小是 64 字节。因此,我最多能存 512 个缓存行到 L1 里。那么如果我们把上面的程序里的矩阵的大小改成 512 之后再跑一下压测,结果会怎样?
BenchmarkMatrixCombination-512 1404 718594 ns/op
BenchmarkMatrixReversedCombination-512 1363 850141 ns/opp
尽管我们已经把两个测试用例的性能差距缩小了很多 (用 64k 大小的矩阵测的时候,第二个要慢了大约 300%),我们还是可以看到会有细微的差距。到底是哪里出了问题?在压测过程中,我们使用了两个矩阵,因此 CPU 需要储存这两个矩阵的所有缓存行。在一个完全理想的状态下 (比如压测过程中没有其他程序在运行,而这几乎是不可能的),L1 缓存会用 50% 的容量来存第一个矩阵而用另外的 50% 的容量来存第二个矩阵。那我们就再进一步缩小两个矩阵的大小,缩减到 256 个元素:
BenchmarkMatrixCombination-256 5712 176415 ns/op
BenchmarkMatrixReversedCombination-256 6470 164720 ns/op
现在我们终于得到了一个近乎相等的压测结果了。
关于为什么第二个测试用例还要略微地比第一个快,这点差别看起来不是很容易察觉而且应该和 Go 编译器生成的汇编代码有关。在第二个测试用例里,第二个矩阵上的指针区别于第一个矩阵指针的管理方式,使用的是 LEA (Load Effective Address) 汇编指令。因为操作系统的虚拟内存机制,当一个处理器访问一个内存地址时,需要做一个虚拟内存到物理真实内存的转换。使用 LEA 指令允许你不经过虚拟内存的转换直接得到内存地址。举个例子,如果我们维护一个由 int64 类型元素组成的切片,我们已经知道了切片里第一个元素的地址,我们就能使用 LEA 指令简单地往后移动 8 个字节得到第二个元素的地址。在我们的例子里,这可能就是为什么第二个测试更快的原因
好了,那我们现在怎么才能在处理一个大容量矩阵时减少处理器缓存缺失带来的影响呢?这里介绍一种叫嵌套循环最优化 (Loop Nest Optimization)的技巧:我们遍历矩阵的时候,每次都以一个指定大小的矩阵块为单位来遍历,以此来最大化利用 CPU 缓存。
在上面的例子里定义一个包含 4 * 4 大小的矩阵块。在第一个矩阵里,我们从 (4,0) 到 (4,3) 遍历一次,然后切换到下一行。相应的,我们在第二个矩阵里就是从 (0,4) 到 (3,4) 遍历一次,然后切换到下一列。
当粉红色指针遍历完第一列之后,处理器就会把相应的的所有缓存行都储存到 L1 里了,因此,遍历剩下的那些元素的时候就都是从 L1 里访问了,这样就能加快速度了:
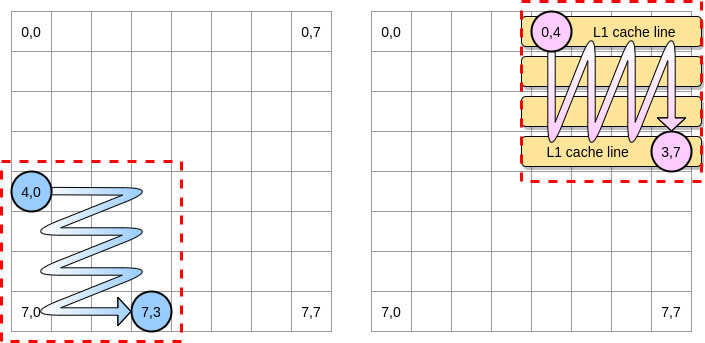
让我们把上述的思路用 Go 实现出来,不过我们得谨慎地选择矩阵块的大小。在之前的例子里,矩阵块的边长等于缓存行的大小,这个值不能设置得再小了,否则的话,缓存行里就会有空余,浪费空间。在我们的 Go 压测程序里,矩阵的元素是 int64 类型 (8 个字节),而缓存行是 64 字节,可以储存 8 个元素,那么矩阵块的边长就至少要是 8:
func BenchmarkMatrixReversedCombinationPerBlock(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
blockSize := 8
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i += blockSize {
for j := 0; j < matrixLength; j += blockSize {
for ii := i; ii < i+blockSize; ii++ {
for jj := j; jj < j+blockSize; jj++ {
matrixA[ii][jj] = matrixA[ii][jj] + matrixB[jj][ii]
}
}
}
}
}
}
现在用这个最新的代码实现去跑压测,结果要比直接遍历整个矩阵的实现快 67%:
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
BenchmarkMatrixReversedCombinationPerBlock-64000 6 185375690 ns/op
这就是用来展示对 CPU 缓存的了解可以如何潜在地帮助我们设计更高效算法的第一个例子。
伪共享 (False Sharing)
经过上面的分析,我们现在应该对处理器如何管理内部缓存有一个比较清晰的理解了;再来快速回顾一下:
- 因为空间局部性原则,处理器会储存缓存行而不是一个单独内存地址。
- L1 缓存是内嵌在指定的 CPU 核心本地的。
要真正理解伪共享,首先要了解 MESI 协议及 RFO 请求:
从前面的内容我们可以知道,每个核心都有自己私有的 L1、L2 缓存。那么多线程编程时, 另外一个核的线程想要访问当前核内 L1、L2 缓存行的数据, 该怎么做呢?
有人说可以通过第 2 个核直接访问第 1 个核的缓存行,这是当然是可行的,但这种方法不够快。跨核访问需要通过 Memory Controller (内存控制器,是计算机系统内部控制内存并且通过内存控制器使内存与 CPU 之间交换数据的重要组成部分),典型的情况是第 2 个核经常访问第 1 个核的这条数据,那么每次都有跨核的消耗。更糟的情况是,有可能第 2 个核与第 1 个核不在一个插槽内,况且 Memory Controller 的总线带宽是有限的,扛不住这么多数据传输。所以,CPU 设计者们更偏向于另一种办法:如果第 2 个核需要这份数据,由第 1 个核直接把数据内容发过去,数据只需要传一次。
那么什么时候会发生缓存行的传输呢?答案很简单:当一个核需要读取另外一个核的脏缓存行时发生。但是前者怎么判断后者的缓存行已经被弄脏(写)了呢?
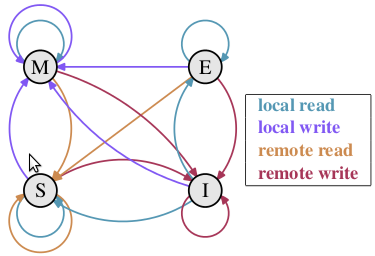
下面将详细地解答以上问题。首先我们需要谈到一个协议—— MESI 协议。现在主流的处理器都是用它来保证缓存的相干性和内存的相干性。M、E、S 和 I 代表使用 MESI 协议时缓存行所处的四个状态:
M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有);
E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝;
I(无效,Invalid):缓存行失效, 不能使用。
下面说明这四个状态是如何转换的:
初始:一开始时,缓存行没有加载任何数据,所以它处于 I 状态。
本地写(Local Write):如果本地处理器写数据至处于 I 状态的缓存行,则缓存行的状态变成 M。
本地读(Local Read):如果本地处理器读取处于 I 状态的缓存行,很明显此缓存没有数据给它。此时分两种情况:(1)其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成 E 状态,表示只有我一家有这条数据,其它处理器都没有;(2)其它处理器的缓存有此行数据,则将此缓存行的状态设为 S 状态。(备注:如果处于M状态的缓存行,再由本地处理器写入/读出,状态是不会改变的)
远程读(Remote Read):假设我们有两个处理器 c1 和 c2,如果 c2 需要读另外一个处理器 c1 的缓存行内容,c1 需要把它缓存行的内容通过内存控制器 (Memory Controller) 发送给 c2,c2 接到后将相应的缓存行状态设为 S。在设置之前,内存也得从总线上得到这份数据并保存。
远程写(Remote Write):其实确切地说不是远程写,而是 c2 得到 c1 的数据后,不是为了读,而是为了写。也算是本地写,只是 c1 也拥有这份数据的拷贝,这该怎么办呢?c2 将发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为 I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置I的过程将给写操作带来很大的性能消耗。
下面添加一个简单的 MESI 状态转换图:
现在,让我们通过一个例子来讨论一下 L1 缓存一致性和伪共享的问题。假设现在有两个变量:var1 和 var2 被储存在主存里,一个在 core1 里的线程访问 var1 ,而另一个 core2 里的线程访问 var2 。假设这两个变量在内存中的位置是相邻的 (或者是非常靠近的),那么最后就会导致 var2 存在于两个核心的同一个 L1 缓存行里:
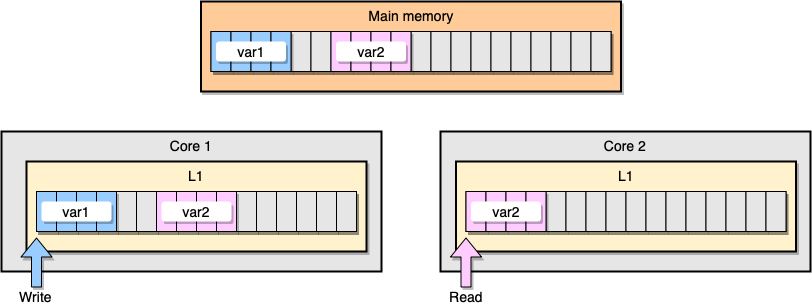
上图中 thread1 位于 core1 ,而 thread2 位于 core2 ,二者均想更新彼此独立的两个变量,但是由于两个变量位于不同核心中的同一个 L1 缓存行中,此时可知的是两个缓存行的状态应该都是 Shared ,而对于同一个缓存行的操作,不同的 core 间必须通过发送 RFO 消息来争夺所有权 (ownership) ,如果 core1 抢到了, thread1 因此去更新该缓存行,把状态变成 Modified ,那就会导致 core2 中对应的缓存行失效变成 Invalid ,当 thread2 取得所有权之后再去更新该缓存行时必须先让 core1 把对应的缓存行刷回 L3 缓存/主存,然后它再从 L3 缓存/主存中加载该缓存行进 L1 之后才能进行修改。然而,这个过程又会导致 core1 对应的缓存行失效变成 Invalid ,这个过程将会一直循环发生,从而导致 L1 高速缓存并未起到应有的作用,反而会降低性能;轮番夺取所有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据,而从前面的内容可以知道,L3 的读取速度相比 L1/L2 要慢了数十倍,性能下降很大;更坏的情况是跨槽读取,L3 都不能命中,只能从主存上加载,那就更慢了。
请记住,CPU 缓存的最小的处理单位永远是缓存行 (Cache Line),所以当某个核心发送 RFO 消息请求把其他核心对应的缓存行设置成Invalid 从而使得 var1 缓存失效的同时,也会导致同在一个缓存行里的 var2 失效,反之亦然。
我们来看一个具体的 Go 程序。在这个例子里,我们相继地实例化了两个结构体,一个紧挨着另一个;因此,这两个结构体应该会被分配在一片连续的内存上;然后,我们再创建两个 goroutines,分别去访问对应的结构体 (变量 M 的值等于 100 万):
type SimpleStruct struct {
n int
}
func BenchmarkStructureFalseSharing(b *testing.B) {
structA := SimpleStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
在这个例子里,第二个结构体里的变量 n 只会被第二个 goroutine 访问,然而,因为两个结构体在内存上的地址是连续的, n 将会存在于两个 CPU 缓存行中 (这里假设两个 goroutine 会被分配到不同核心上调度,当然,这通常不是必须的),这是压测结果:
BenchmarkStructureFalseSharing 514 2641990 ns/op
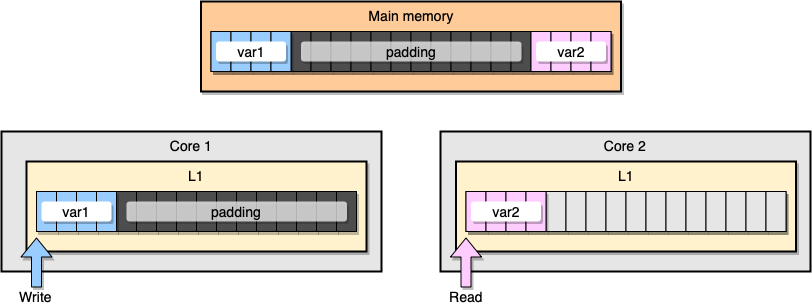
那么我们如何才能规避这种伪共享呢?有一个解决办法是使用内存填充 (memory padding)。这种方案的原理是在两个变量之间填充足够多的空间,以确保它们会储存在不同的 CPU 缓存行里。
首先,让我们创建一个替代之前那个结构体的新结构体,在变量声明之后填充足够的内存:
type PaddedStruct struct {
n int
_ CacheLinePad
}
type CacheLinePad struct {
_ [CacheLinePadSize]byte
}
const CacheLinePadSize = 64
接着,我们再初始化这两个结构体而且和之前一样通过单独的 goroutine 分别去访问这两个变量:
func BenchmarkStructurePadding(b *testing.B) {
structA := PaddedStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
内存智能化,这个例子里的内存分布应该看起来像下图这样,两个变量之间留有足够多的内存填充,从而导致它们最后只会分别存在于不同核心的缓存行上:
让我们来看下最新的压测结果:
BenchmarkStructureFalseSharing 514 2641990 ns/op
BenchmarkStructurePadding 735 1622886 ns/op
使用了内存填充之后的第二个例子要比最初的那个快了差不多 40% ????,虽然不是没有代价的。内存填充的确能加快执行时间,不过代价是会导致更多的内存分配和浪费。
Go语言:同步
Happens Before
在多线程的环境中,多个线程或协程同时操作内存中的共享变量,如果不加限制的话,就会出现出乎意料的结果。想保证结果正确,就需要在时序上让来自不同线程的访问串行化,彼此之间不出现重叠。
线程对变量的操作一般就是Load和Store两种,就是我们俗称的读和写。Happens Before也可以认为是对一种串行化描述或要求,目的是保证某个线程对变量的写操作,能够被其他的线程正确的读到。
按照字面含义,你可能会认为,如果事件e2在时序上于事件e1结束后发生,那么就可以说事件e1 happens before e2了。按照一般常识应该是这样的,在我们介绍内存乱序之前你暂时可以这样理解,事实上这对于多核环境下的内存读写操作来讲是不够的。
如果e1 happens before e2,那么也可以说成e2 happens after e1。若要保证对变量v的某个读操作r,能够读取到某个写操作w写入到v的值,必须同时满足以下条件:
- w happens before r;
- 没有其他针对v的写操作happens after w且before r。
如果e1既不满足happens before e2,又不满足happens after e2,那么就认为e1与e2之间存在并发。
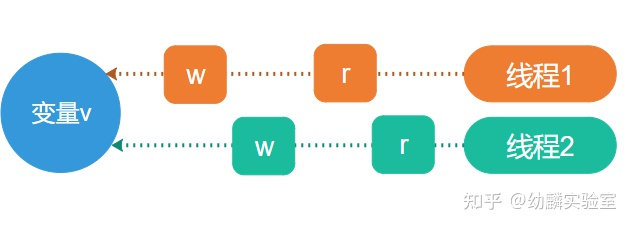
单个线程或协程内部访问某个变量是不存在并发的,默认就能满足happens before条件,因此某个读操作总是能读到之前最近一次写操作写入的值。但是在多个线程或协程之间就不一样了,因为存在并发的原因,必须通过一些同步机制来实现串行化,以确立happens before条件。
并发和并行
在单核CPU上分时交替运行的多个线程,可以认为是最经典的并发场景。宏观上看起来同时在运行的多个线程,微观上是以极短时间片交替运行在同一个CPU上。在多核CPU出现以前,并发指的就是这么一种情况。但是在多核CPU出现以后,并发就不像以前那么简单了,不仅仅是微观上的分时运行,还包含了并行的情况。
抽象的解释并发的话,指的是多个事件在宏观上是同时发生的,但是并不一定要在同一时刻发生。而并行就不一样了,从微观角度来看,并行的两个事件至少有某一时刻是同时发生的。所以在单核CPU上的多线程只存在并发,不存在并行。只有在多核CPU上,线程才有可能并行执行。
内存乱序
一般来讲,我们认为代码会按照编写的顺序来执行,也就是逐语句、逐行的按顺序执行。然而事实并非如此,编译器有可能对指令顺序进行调整,处理器普遍具有乱序执行的特性,目的都是为了更优的性能。
操作内存的指令可以分成Load和Store两类,也就是按读和写划分。编译器和CPU都会考虑指令间的依赖关系,在不会改变当前线程行为的前提下进行顺序调整,因此在单个线程内依然是逻辑有序的。但这种有序性只是在单个线程内,并不会保证线程间的有序性。
程序中的共享变量都是位于内存中的,指令顺序的变化会让多个线程同时读写内存中的共享变量产生意想不到的结果。这种因指令乱序造成的内存操作顺序与预期不一致的问题,就是我们所谓的内存乱序。
编译期乱序
所谓的编译期乱序,指的就是编译器对最终生成的机器指令进行了顺序调整,一般是出于性能优化的目的。造成的影响就是,机器指令的顺序与源代码中语句的顺序并不是严格匹配。这种乱序在C++中很常见,尤其是在编译器的优化级别比较高的时候。这一问题最常用的解决方法就是使用compiler barrier,俗称“编译屏障”。编译屏障会阻止编译器跨屏障移动指令,但是仍然可以在屏障的两侧分别移动。在GCC中,常用的编译屏障就是在两条语句之间嵌入一个空的汇编语句块:
data = someValue;
asm volatile("" :::"memory"); // compiler barrier
ok = true;
但是加上编译屏障后,依然无法保证程序能够在各个平台上如预期的运行,原因就是CPU在执行期间也可能会对指令的顺序进行调整,也就是所谓的“执行期乱序”。
执行期乱序
先用一段代码来让大家亲自见证执行期乱序,这样更有助于后续内容的理解。下面这段代码使用Go语言来实现,平台是amd64:
func main() {
s := [2]chan struct{}{
make(chan struct{}, 1),
make(chan struct{}, 1),
}
f := make(chan struct{}, 2)
var x, y, a, b int64
go func() {
for i := 0; i < 1000000; i++ {
<-s[0]
x = 1
b = y
f <- struct{}{}
}
}()
go func() {
for i := 0; i < 1000000; i++ {
<-s[1]
y = 1
a = x
f <- struct{}{}
}
}()
for i := 0; i < 1000000; i++ {
x = 0
y = 0
s[i%2] <- struct{}{}
s[(i+1)%2] <- struct{}{}
<-f
<-f
if a == 0 && b == 0 {
println(i)
}
}}
代码中一共有3个协程,4个int类型的共享变量,3个协程都会循环100万次,3个channel用来同步每次循环。循环开始时先由主协程将x、y清零,然后通过切片s中的两个channel让其他两个协程开始运行。协程1在每轮循环中先把1赋值给x,再把y赋值给b。协程2在每轮循环中先把1赋值给y,再把x赋值给a。f用来保证在每轮循环中都等到两个协程完成赋值操作后,主协程才去检测a和b的值,两者同时为0时会打印出当前循环的次数。
a和b的取值会有几种可能?
从源码角度来看,无论如何a和b都不应该同时等于0。如果协程1完成赋值后协程2才开始执行,结果就是a等于1而b等于0,反过来就是a等于0而b等于1。如果两个协程的赋值语句并行执行,那么结果就是a和b都等于1。然而实际运行的话,会发现大量打印输出,根本原因就是出现了执行期乱序。注意,执行期乱序要在并行环境下才能体现出来,单个CPU核心自己是不会体现出乱序的。Go程序可以使用GOMAXPROCS环境变量来控制并发度,针对上述示例代码,GOMAXPROCS设置为1的话即使在多核心CPU上也不会出现乱序。
为什么a和b会同时等于0?
协程一、二中的两条赋值语句形式相似,对应到x86汇编就是三条内存操作指令,按顺序分别是Store、Load、Store。
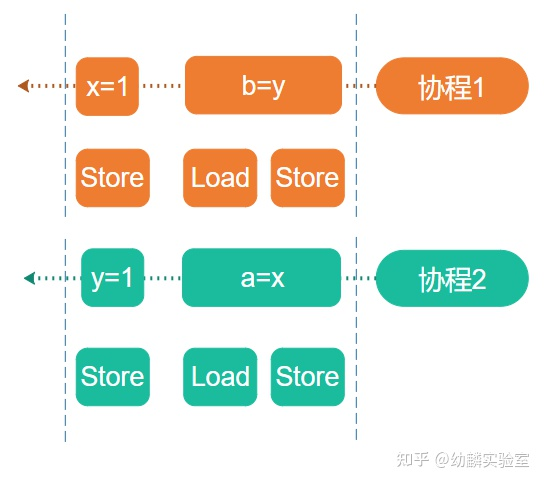
出现的乱序问题就是由前两条指令造成的,称为Store-Load乱序,这也是当前的x86架构CPU上能够观察到的唯一一种乱序。Store和Load分别操作的是不同的内存地址,从现象来看就像是先执行的Load而后执行的Store。
为什么会出现Store-Load乱序呢?
我们知道现在的CPU普遍带有多级指令和数据缓存,指令执行系统也是流水线式的,可以让多条指令同时在流水线上执行。一般的内存都属于write-back cacheable内存,简称WB内存。对于WB内存而言,Store和Load指令并不是直接操作内存中的数据,而是先把指定的内存单元填充到高速缓存中,然后读写高速缓存中的数据。Load指令的大致流程:先尝试从高速缓存中读取,如果缓存命中,读操作就完成了。
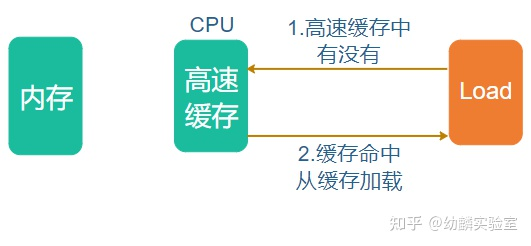
如果缓存未命中,那么先填充对应的cache line,然后从cache line中读取:
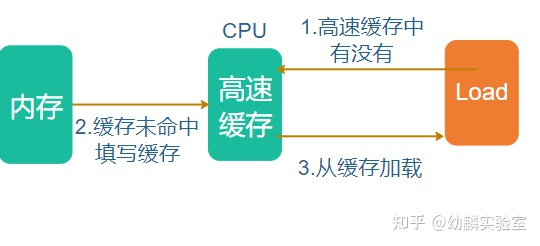
Store指令的大致流程类似,先尝试写高速缓存,如果缓存命中,写操作就完成了。如果缓存未命中,那么先填充对应的cache line,然后写到内存中:
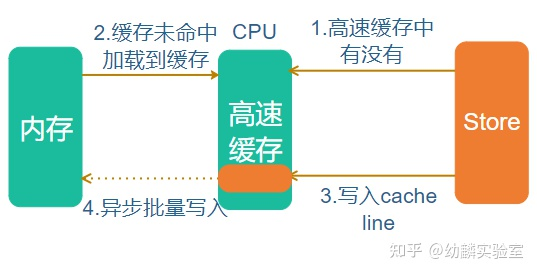
可能有些读者会对Store操作写之前要先填充cache line感到疑惑,那是因为高速缓存和内存之间的数据传输不是以字节为单位的,最小单位就是一个cache line。cache line大小因处理器的架构而异,常见的大小有32、64及128字节等。
在多核心的CPU上,Store操作会变的更复杂一些。每个CPU核心都拥有自己的高速缓存,例如x86的L1 Cache。写操作会修改当前核心的高速缓存,被修改的数据可能存在于多个核心的高速缓存中,CPU需要保证各个核心间的缓存一致性。目前主流的缓存一致性协议是MESI协议,MESI这个名字取自缓存单元可能的4种状态,分别是已修改Modified,独占的Exclusive,共享的Shared,和无效的Invalid。当一个CPU核心要对自身高速缓存的某个单元进行修改时,它需要先通知其他CPU核心把各自高速缓存中对应的单元置为Invalid,再把自己的这个单元置为Exclusive,然后就可以进行修改了。

这个过程涉及多核间内部通信,是一个相对较慢的过程,为了避免当前核心因为等待而阻塞,CPU在设计上又引入了Store Buffer。当前核心向其他核心发出通知以后,可以先把要写的值放在Store Buffer中,然后继续执行后面的指令,等到其他核心完成响应以后,当前核心再把Store Buffer中的值合并到高速缓存中。

虽然高速缓存会保证多核一致性,但是Store Buffer却是各个核心私有的,对其他核心不可见。在Store-Load乱序中,从微观时序上,Load指令可能是在另一个线程的Store之后执行,但此时多核间通信尚未完成,对应的缓存单元还没有被置为Invalid,Store Buffer也没有被合并到高速缓存中,所以Load读到的是修改前的值。

如上图所示,如果协程1执行的Store命令,x的新值只是写入CPU1的Store Buffer,尚未合并到高速缓存,此时协程2执行Load指令拿到的x就是修改前的旧值0,而不是1。同样的,协程2修改y的值也可能只写入的CPU2的Store Buffer,所以协程1执行Load指令加载的y的值就是旧值0。

而当协程1执行最后一条Store指令时,b就被附值为0;同样的,协程2会将a附值为0。即使Store Buffer合并到高速缓存,x和y都被修改为新值,也已经晚了。
我们通过代码示例见证了x86的Store-Load乱序,Intel开发者手册上说x86只会出现这一种乱序。抛开固定的平台架构,理论上可能出现的乱序有4种:
- Load-Load,相邻的两条Load指令,后面的比前面的先读到数据;
- Load-Store,Load指令在前Store指令在后,但是Store操作先变成全局可见,Load指令在此之后才读到数据;
- Store-Load,Store指令在前Load指令在后,但是在Load指令先读到了数据,Store操作在此之后才变成全局可见。这个我们已经在x86平台见证过了;
- Store-Store,相邻的两条Store指令,后面的比前面的先变成全局可见。
所谓的全局可见,指的就是在多核CPU上对所有核心可见。因为笔者手边只有amd64架构的工作电脑,暂时无法见证其他几种乱序,有条件的读者可以在其他的架构上尝试一下。比如通过以下代码应该可以发现Store-Store乱序:
func main() {
var wgsync.WaitGroup
var x, yint64
wg.Add(2)
go func() {
defer wg.Done()
for i := 0; i < 1000000000; i++ {
if x == 0 {
if y != 0 {
println("1:", i)
}
x = 1
y = 1
}
}
}()
go func() {
deferwg.Done()
for i := 0;i < 1000000000; i++ {
if y == 1 {
if x != 1 {
println("2:",i)
}
y= 0
x= 0
}
}
}()
wg.Wait()
}
内存排序指令
执行期乱序会给结果带来很大的不确定性,这对于应用程序来说是不能接受的,完全按照指令顺序执行又会使性能变差。为了解决这一问题,CPU提供了内存排序指令,应用程序在必要的时候能够通过这些指令来避免发生乱序。以目前的Intel x86处理器为例,就提供了LFENCE、SFENCE和MFENCE这3条内存排序指令,接下来我们就逐一分析一下它们的作用。
LFENCE
LFENCE是LoadFence的缩写,Fence翻译成中文是栅栏,可以认为起到分隔的作用,它会对当前核心上LFENCE之前的所有Load类指令进行序列化操作。具体来说,针对当前CPU核心,LFENCE会在之前的所有指令都执行完后才开始执行,并且在LFENCE执行完之前,不会有后续的指令开始执行。特别是,LFENCE之前的Load指令,一定会在LFENCE执行完成之前从内存接收到数据。LFENCE不会针对Store指令,Store指令之后的LFENCE可能会在Store写入的数据变成全局可见前执行完成。LFENCE之后的指令可以提前被从内存中加载,但是在LFENCE执行完之前它们不会被执行,即使是推测性的。以上主要是Intel开发者手册对LFENCE的解释,它原本被设计用来阻止Load-Load乱序。让所有后续的指令在之前的指令执行完后才开始执行,这是Intel对它功能的一个扩展,因此理论上它应该也能阻止Load-Store乱序。考虑到目前的x86 CPU不会出现这两种乱序,所以编程语言中暂时没有用到LFENCE指令来进行多核同步,未来也许会用到。Go的runtime中用到了LFENCE的扩展功能来对RDTSC进行序列化,但是这并不属于同步的范畴。
SFENCE
SFENCE是StoreFence的缩写,它能够分隔两侧的Store指令,保证之前的Store操作一定会在之后的Store操作变成全局可见前先变成全局可见。结合前一小节的高速缓存和Store Buffer,笔者猜测SFENCE影响到Store Buffer合并到高速缓存的顺序。根据上述解释,SFENCE应该主要是用来应对Store-Store乱序,由于现阶段的x86 CPU也不会出现这种乱序,所以编程语言暂时也未用到它来进行多核同步。
MFENCE
MFENCE是MemoryFence的缩写,它会对之前所有的Load和Store指令进行序列化操作,这个序列化会保证MFENCE之前的所有Load和Store操作会在之后的任何Load和Store操作前先变成全局可见。所以上述3条指令中,只有MFENCE能够阻止Store-Load乱序。我们对之前的示例代码稍作修改,尝试使用MFENCE指令来阻止Store-Load乱序,新的示例中用到了汇编语言,所以需要两个源码文件。首先是汇编代码文件fence_amd64.s:
#include "textflag.h"
// func mfence()
TEXT ·mfence(SB), NOSPLIT, $0-0
MFENCE
RET
接下来是修改过的Go代码,被放置在fence.go文件中,跟之前会发生乱序的代码只有一点不同,就是在Store和Load之间插入了MFENCE指令。如下所示:
package main
func main() {
s :=[2]chan struct{}{
make(chanstruct{}, 1),
make(chan struct{}, 1),
}
f := make(chan struct{}, 2)
var x, y, a, b int64
go func() {
for i := 0; i <1000000; i++ {
<-s[0]
x = 1
mfence()
b = y
f <-struct{}{}
}
}()
go func() {
for i := 0;i < 1000000; i++ {
<-s[1]
y = 1
mfence()
a = x
f <-struct{}{}
}
}()
for i := 0;i < 1000000; i++ {
x = 0
y = 0
s[i%2] <- struct{}{}
s[(i+1)%2] <- struct{}{}
<-f
<-f
if a == 0 && b == 0 {
println(i)
}
}
}
func mfence()
编译执行上述代码,就会发现之前的Store-Load乱序不见了,程序不会有任何打印输出。如果将MFENCE指令换成LFENCE或SFENCE,就无法达到同样的目的了,感兴趣的读者可以自己尝试一下。